



Once you’ve trained a machine learning model, the next crucial step is to operationalize it. Machine learning operations, or MLOps, help you scale your model from a proof of concept to full production, ensuring that the model is robust, reproducible, and ready for large-scale deployment. By implementing MLOps, you can automate the retraining and redeployment of your models to maintain their performance over time.
In this post, we’ll explore a typical MLOps architecture and the key considerations for bringing a model into production.
Key Elements of an MLOps Solution
MLOps involves much more than just deploying a model. It encompasses designing an infrastructure that allows for seamless retraining, monitoring, and scaling. Here’s a breakdown of the primary components:
- MLOps Architecture: Building a reliable, scalable infrastructure for development and production environments.
- Monitoring: Continuously track the model’s performance, data quality, and infrastructure utilization.
- Retraining: Automating model retraining based on predefined schedules or key performance metrics.
Designing an MLOps Architecture
An effective MLOps architecture ensures that your machine learning models are easily deployable and maintainable over time. Here’s a common approach to structuring your MLOps architecture:
- Development environment: Experiment with model training and development.
- Pre-production environment: Deploy and test the model in a controlled setting.
- Production environment: Deploy the model for end-users to consume predictions.

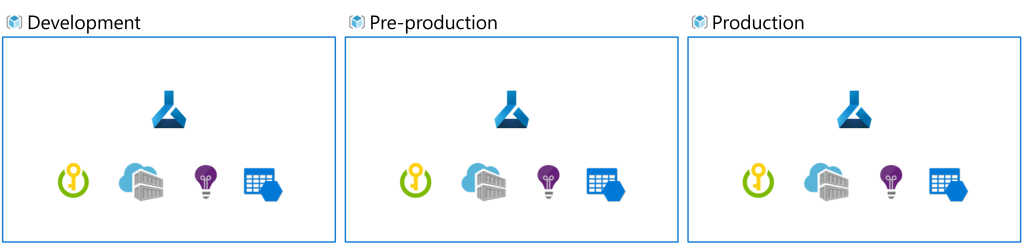
In each stage, a combination of data engineers, machine learning engineers, and infrastructure teams collaborate to ensure the solution runs smoothly. Data engineers manage data storage and pipelines, while machine learning engineers focus on deploying and monitoring models in production.
To manage access and security, you can use Azure Machine Learning workspaces with role-based access control (RBAC). Each environment (development, pre-production, and production) may have its own workspace, providing clear boundaries between testing and production.
Tip: Learn more about best practices for organizing Azure Machine Learning resources.
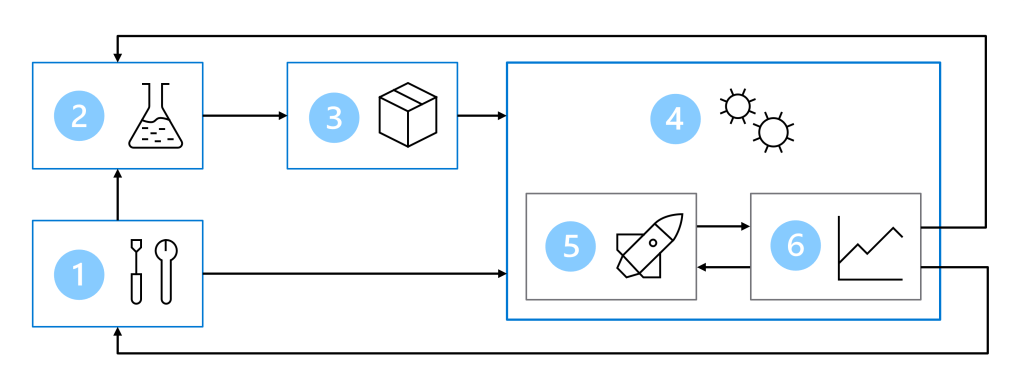
As a result, your MLOps architecture includes the following parts:
- Setup: Create all necessary Azure resources for the solution.
- Model development (inner loop): Explore and process the data to train and evaluate the model.
- Continuous integration: Package and register the model.
- Model deployment (outer loop): Deploy the model.
- Continuous deployment: Test the model and promote to production environment.
- Monitoring: Monitor model and endpoint performance.

Monitoring in MLOps
Once your model is deployed, monitoring its performance is critical to ensure it remains accurate and efficient. There are three main areas to monitor:

1. Model Performance
Tracking key metrics like accuracy, precision, or recall helps you evaluate whether the model is delivering as expected. You can set performance benchmarks and receive alerts when the model falls below acceptable levels. Monitoring also includes tracking fairness and ensuring that the model continues to make unbiased predictions.
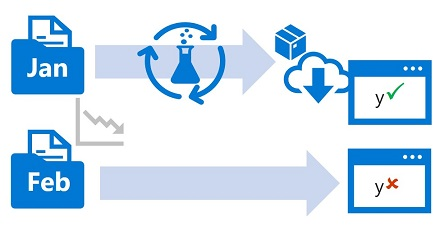
2. Data Drift
Over time, the data used to train a model may no longer reflect new trends, leading to a phenomenon called data drift. If the data profile changes significantly, the model’s predictions can become less accurate. Monitoring for data drift helps detect when retraining is necessary to maintain performance.
3. Infrastructure Utilization
Optimizing compute usage is key to managing costs. By monitoring compute utilization during both training and deployment, you can decide when to scale up or down based on demand, ensuring efficient use of resources.
Tip: Learn more about monitoring your Azure Machine Learning workspace and resources.
Designing for Model Retraining
Retraining models is an essential part of any MLOps solution. Whether retraining on a schedule or based on performance metrics, designing for retraining ensures that your models stay relevant and accurate.
Scheduled Retraining
You may decide to retrain models at regular intervals, such as weekly or monthly, to keep them updated with the latest data. This approach is useful when continuous accuracy is critical, such as in dynamic industries where data changes rapidly.
Retraining Based on Metrics
In some cases, it’s more efficient to retrain only when performance metrics indicate a decline. By monitoring for data drift or performance drops, you can trigger retraining processes only when necessary.
Automating the Retraining Process
To enable smooth retraining, automation is key. Here are two important steps to prepare your retraining process:
- Use Parameterized Scripts: Train models using scripts rather than notebooks, as scripts are better suited for automation. By parameterizing scripts, you can easily adjust inputs like training data and hyperparameters, making it easier to rerun the process with new data.
- Automate with Pipelines: Azure Machine Learning allows you to schedule pipelines to automatically execute retraining scripts. You can trigger these pipelines based on events or schedule them to run periodically, ensuring the model stays up-to-date.
Tools like Azure DevOps and GitHub Actions are commonly used in MLOps to manage automation workflows and trigger retraining. These tools can integrate with Azure Machine Learning to streamline the entire process.
Tip: Explore how to build your first MLOps pipeline with GitHub Actions.
Conclusion
Implementing a solid MLOps solution ensures that your machine learning models are not only deployed effectively but also maintained and retrained to stay accurate over time. From setting up development and production environments to monitoring model performance and automating retraining, MLOps provides the structure needed for reliable, scalable machine learning in production.
Whether you are building your first machine learning model or managing a portfolio of models at scale, designing for MLOps is crucial for long-term success.
This blog post is based on information and concepts derived from the Microsoft Learn module titled “Design a machine learning operations solution.” The original content can be found here:
https://learn.microsoft.com/en-us/training/modules/design-machine-learning-operations-solution/
Deixe um comentário Cancelar resposta