



Once you’ve trained a machine learning model, the next critical step is to deploy it in a way that ensures it reaches your target users. Whether the goal is to boost internal productivity or enhance the user experience for customers, deploying the model to an endpoint is essential for integrating it into applications or services.
In this guide, we’ll explore how to design a model deployment solution that meets user needs and takes into account the technical requirements of the model.
Key Considerations for Model Deployment
Before deploying your model, you need to consider how it will be used. This involves understanding the type of predictions needed—real-time or batch—and planning how the model will be integrated into applications.
The process of deploying and integrating a model follows these key steps:


- Define the problem: Understand what the model should predict and how success will be measured.
- Gather the data: Identify and access the necessary data.
- Prepare the data: Clean and transform the data for training.
- Train the model: Choose algorithms and fine-tune hyperparameters.
- Deploy the model: Integrate the model into applications via an endpoint.
- Monitor the model: Continuously track and improve model performance.
This process is iterative. Monitoring can reveal the need for model retraining and adjustments over time.
Deploying a Model to an Endpoint
The goal of model deployment is to integrate the model into an application. With Azure Machine Learning, you can deploy your model to an endpoint, which can be called by an application to get predictions. Endpoints act as web addresses that return results when called by external applications.
When deploying a model to an endpoint, there are two main types of predictions:
- Real-time predictions: Immediate predictions for incoming data.
- Batch predictions: Predictions generated for a collection of data at specific intervals.
Real-time Predictions
Real-time predictions are often required when the model is integrated into applications like websites or mobile apps. For instance, a product recommendation model on an e-commerce site may offer suggestions based on a customer’s selection.


Imagine a customer selects a shirt on your website. The model immediately recommends related items, ensuring a smooth, real-time shopping experience. The time it takes to load the product page is the same time frame in which the recommendations are displayed.
Batch Predictions
Batch predictions are used when you collect data over time and process it all at once. For example, forecasting future sales based on weekly data falls into this category. You might gather sales data throughout the week and generate predictions at the end of the week to include in a report.


While real-time predictions are needed for instant decision-making, batch predictions are better suited for scheduled analyses where immediate results aren’t critical.
Deciding Between Real-time and Batch Deployment
Choosing between real-time and batch deployment depends on several factors:
- Frequency of predictions: How often do you need predictions—immediately or at set intervals?
- Timing of results: How quickly do you need the predictions?
- Compute power required: How much processing power is needed to execute the model?
Real-time or Batch: How to Decide
To determine whether to deploy your model for real-time or batch predictions, consider:
- How often predictions are needed: If predictions must be generated as soon as data arrives, real-time is necessary. If predictions can wait until a batch of data is available, batch processing may be more efficient.
- Timing of data collection: Real-time deployment is best for constant data flow, such as IoT sensor readings every minute. Batch deployment is suited for periodic data collection, like financial reports generated every quarter.
- Number of predictions: If you need predictions for each individual data point, real-time is the way to go. If predictions are generated for multiple data points at once, batch processing is more efficient.
Compute Considerations for Deployment
The type of compute you need depends on whether you’re deploying the model for real-time or batch predictions. Each has distinct compute requirements:
- Real-time compute: Requires always-on compute infrastructure, such as Azure Kubernetes Service (AKS) or Azure Container Instance (ACI). Real-time deployment involves continuous costs because the model must be ready to serve predictions immediately.
- Batch compute: Uses scalable compute clusters that can handle large datasets in parallel. The cluster scales up when processing is needed and scales down to zero when idle, reducing costs significantly.

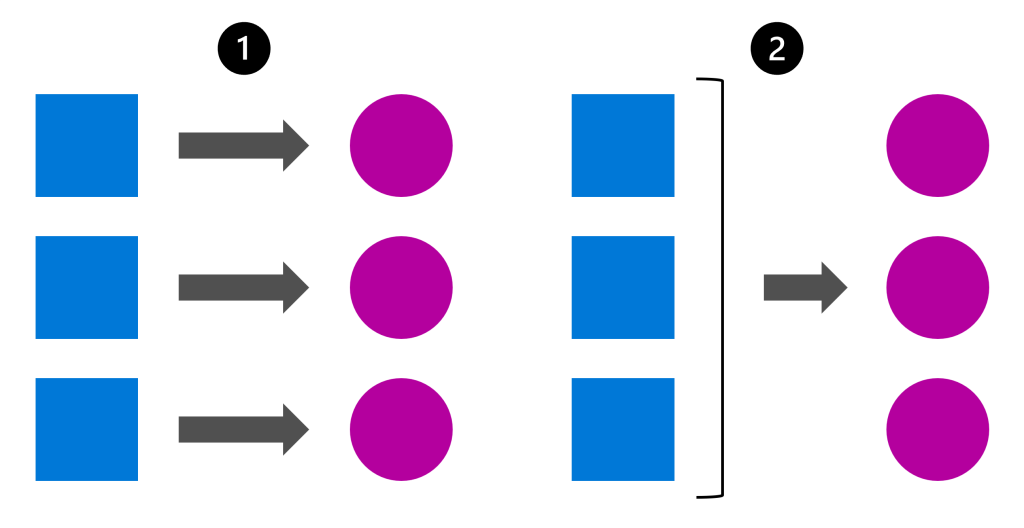
For real-time predictions, the cost of compute is ongoing, while batch predictions offer a more cost-effective solution, especially for use cases where predictions don’t need to be instantaneous.
Conclusion: Finding the Right Balance
When designing a model deployment solution, the decision between real-time and batch predictions often comes down to balancing speed and cost. If predictions are needed immediately for a high-frequency application, real-time deployment is the best option. However, if predictions can be delayed and cost savings are a priority, batch processing may be more efficient.
In either case, carefully consider the computational requirements of your model. Simpler models require less compute, while complex models may need more powerful infrastructure. Plan your deployment strategy accordingly, ensuring that it aligns with both technical needs and business goals.
This blog post is based on information and concepts derived from the Microsoft Learn module titled “Design a model deployment solution.” The original content can be found here:
https://learn.microsoft.com/en-us/training/modules/design-model-deployment-solution/
Deixe um comentário Cancelar resposta