



Apache Spark: A Powerhouse for Big Data
In today’s data-driven world, the ability to efficiently process and analyze massive datasets is paramount. Apache Spark, an open-source parallel processing framework, has emerged as a leading solution for tackling “big data” challenges. Its popularity stems from its ability to handle diverse data processing and analytics tasks at scale.
Spark in Microsoft Fabric: A Seamless Integration
While Spark is available in various platform implementations, its integration within Microsoft Fabric brings unique advantages. Fabric provides a unified environment where you can leverage Spark alongside other powerful data services. This seamless integration simplifies the incorporation of Spark-based data processing into your broader data analytics workflows.
Prepare to Use Apache Spark
Distributed Processing with Spark
Apache Spark is a powerful distributed data processing framework that revolutionizes large-scale data analytics. It achieves this by orchestrating work across multiple processing nodes within a cluster, referred to as a Spark pool in Microsoft Fabric. Essentially, Spark employs a “divide and conquer” strategy to process vast amounts of data rapidly by distributing the workload across multiple computers. The intricate process of task distribution and result collation is seamlessly managed by Spark itself.
Spark’s Language Versatility
Spark supports code written in various languages, including Java, Scala (a Java-based scripting language), Spark R, Spark SQL, and PySpark (a Python variant tailored for Spark). In practice, the majority of data engineering and analytics tasks are accomplished through a combination of PySpark and Spark SQL, leveraging their strengths for different aspects of data processing.
Understanding Spark Pools
A Spark pool is a collection of compute nodes responsible for distributing data processing tasks. Its architecture involves two key node types:
- Head Node: This node acts as the coordinator, orchestrating distributed processes through a driver program.
- Worker Nodes: These nodes host executor processes that execute the actual data processing tasks.
The Spark pool leverages this distributed compute architecture to seamlessly access and process data stored in compatible data stores, such as a lakehouse built on OneLake.


Spark Pools in Microsoft Fabric
Microsoft Fabric provides a convenient starter pool within each workspace, enabling quick initiation and execution of Spark jobs with minimal configuration. You can customize the starter pool’s node configuration to align with your specific workload requirements or cost considerations.
Moreover, you have the flexibility to create custom Spark pools with tailored node configurations to address your unique data processing needs.
Note: Fabric administrators have the authority to disable Spark pool customization at the Fabric Capacity level. Refer to the Fabric documentation for details on “Capacity administration settings for Data Engineering and Data Science.”
You can manage starter pool settings and create new Spark pools within the Data Engineering/Science section of your workspace settings. Key configuration options include:
- Node Family: Choose the type of virtual machines for your Spark cluster nodes. Memory-optimized nodes are typically recommended for optimal performance.
- Autoscale: Enable or disable automatic node provisioning based on demand. If enabled, specify the initial and maximum number of nodes for the pool.
- Dynamic Allocation: Control the dynamic allocation of executor processes on worker nodes according to data volumes.
If you create custom Spark pools, you can designate one as the default pool, used automatically unless a specific pool is explicitly specified for a Spark job.
Tip: Consult the Microsoft Fabric documentation for in-depth information about managing Spark pools.
https://learn.microsoft.com/en-us/fabric/data-engineering/configure-starter-pools


Runtimes and Environments
The Spark open-source ecosystem encompasses various runtime versions. The runtime determines the versions of Apache Spark, Delta Lake, Python, and other core software components installed. Moreover, you can install and utilize a wide array of code libraries within a runtime to handle common and specialized tasks. Given the prevalence of PySpark in Spark processing, the extensive collection of Python libraries ensures a solution for virtually any task.
In some scenarios, organizations might require multiple environments to support diverse data processing needs. Each environment specifies a particular runtime version and the necessary libraries for specific operations. Data engineers and scientists can then choose the appropriate environment for their Spark pool and task.
Spark Runtimes in Microsoft Fabric
Microsoft Fabric supports multiple Spark runtimes and will continue to expand its support as new versions are released. You can define the default Spark runtime for your workspace’s default environment in the workspace settings.
Tip: Refer to the Microsoft Fabric documentation for more information about Spark runtimes.
https://learn.microsoft.com/en-us/fabric/data-engineering/runtime
Environments in Microsoft Fabric
Custom environments within a Fabric workspace empower you to tailor Spark runtimes, libraries, and configuration settings for various data processing operations. When creating an environment, you can:
- Specify the desired Spark runtime.
- Review built-in libraries.
- Install public libraries from PyPI.
- Install custom libraries by uploading package files.
- Designate the Spark pool for the environment.
- Override default behavior with Spark configuration properties.
- Upload necessary resource files.
After creating custom environments, you can set one as the default in your workspace settings.
Tip: Explore the Microsoft Fabric documentation for detailed instructions on using custom environments.
https://learn.microsoft.com/en-us/fabric/data-engineering/create-and-use-environment

Additional Spark Configuration Options
While managing Spark pools and environments are primary configuration methods, Microsoft Fabric offers additional options for further optimization.
Native Execution Engine
The native execution engine in Microsoft Fabric is a vectorized processing engine that executes Spark operations directly on the lakehouse infrastructure. This can lead to significant performance improvements for queries on large Parquet or Delta datasets.
Enable the native execution engine at the environment level or within individual notebooks using specific Spark properties.
Tip: The Microsoft Fabric documentation provides comprehensive information on the native execution engine.
https://learn.microsoft.com/en-us/fabric/data-engineering/native-execution-engine-overview?tabs=sparksql
High Concurrency Mode
Spark sessions are initiated when you run Spark code in Microsoft Fabric. High concurrency mode optimizes Spark resource usage by sharing sessions across multiple concurrent users or processes. This enables efficient code execution in notebooks and Spark jobs while maintaining isolation.
You can enable high concurrency mode in the workspace settings.
Tip: For details on high concurrency mode, refer to the Microsoft Fabric documentation.
https://learn.microsoft.com/en-us/fabric/data-engineering/high-concurrency-overview
Automatic MLFlow Logging
MLFlow is an open-source library for managing machine learning training and model deployment in data science. It offers the capability to log model-related operations. Microsoft Fabric utilizes MLFlow for implicit logging of machine learning experiments by default. You can disable this in the workspace settings.
Spark Administration for a Fabric Capacity
Administrators can manage Spark settings at the Fabric capacity level, allowing them to restrict and override Spark settings within an organization’s workspaces.
By understanding these key concepts and configuration options, you’ll be well-prepared to leverage Apache Spark effectively within Microsoft Fabric for your data processing and analytics needs.
Run Spark code
Notebooks for Interactive Exploration
When your goal is to interactively explore and analyze data using Spark, notebooks are your go-to tool. These versatile documents seamlessly combine text, images, and code written in multiple languages, creating an interactive platform that fosters collaboration and sharing.
Notebooks consist of individual cells, each capable of holding either markdown-formatted content for documentation or executable code. The interactive nature of notebooks allows you to run code cells and instantly view the results, making them ideal for experimentation and iterative development.


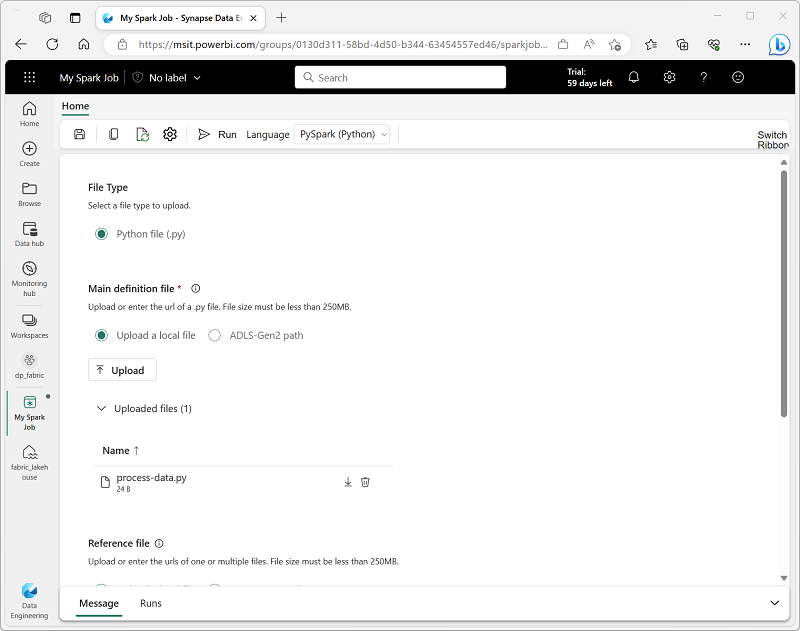
Spark Job Definition for Automation
For scenarios where you need to ingest and transform data using Spark as part of an automated process, you can define a Spark job. This enables you to execute a script either on-demand or based on a predefined schedule.
To set up a Spark job, create a Spark Job Definition within your workspace and specify the script you want to run. You also have the option to provide a reference file (e.g., a Python code file containing function definitions used in your script) and a reference to the specific lakehouse where your script will process data.
This blog post is based on information and concepts derived from the Microsoft Learn module titled “Use Apache Spark in Microsoft Fabric.” The original content can be found here:
https://learn.microsoft.com/en-us/training/modules/use-apache-spark-work-files-lakehouse/
Deixe um comentário Cancelar resposta